An Overview of Analyzing Schema Duplication with NLP
BY
Asante Babers
/
Nov 10, 2024
/
Log Analysis
/
5 Min
Read
An Overview of Analyzing Schema Duplication with NLP
Log data is the backbone of detection engineering, helping organizations monitor systems and detect threats. However, the issue of duplicate data in log sources can lead to inflated storage requirements, slower analysis, and unnecessary noise in threat detection workflows. In this post, we explore how Natural Language Processing (NLP) can help identify and reduce duplication in log schemas, and we dive into the broader implications of these findings.
My study of 207 schemas from Panther revealed significant redundancies, with some schemas containing over 80% duplicate fields. By addressing these duplications, organizations can streamline their log management processes and optimize storage and processing requirements.
What is a "Duplicate Field"?
In the context of log analysis, a duplicate field refers to information that appears in multiple log sources but conveys the same meaning. For example:
Two fields representing an IP address but coming from distinct log sources.
Fields capturing the same user action but named differently in distinct log sources.
Duplicate fields inflate log volume unnecessarily, creating noise and increasing storage and processing costs.
Key Findings
Duplication Rates Across Log Schemas
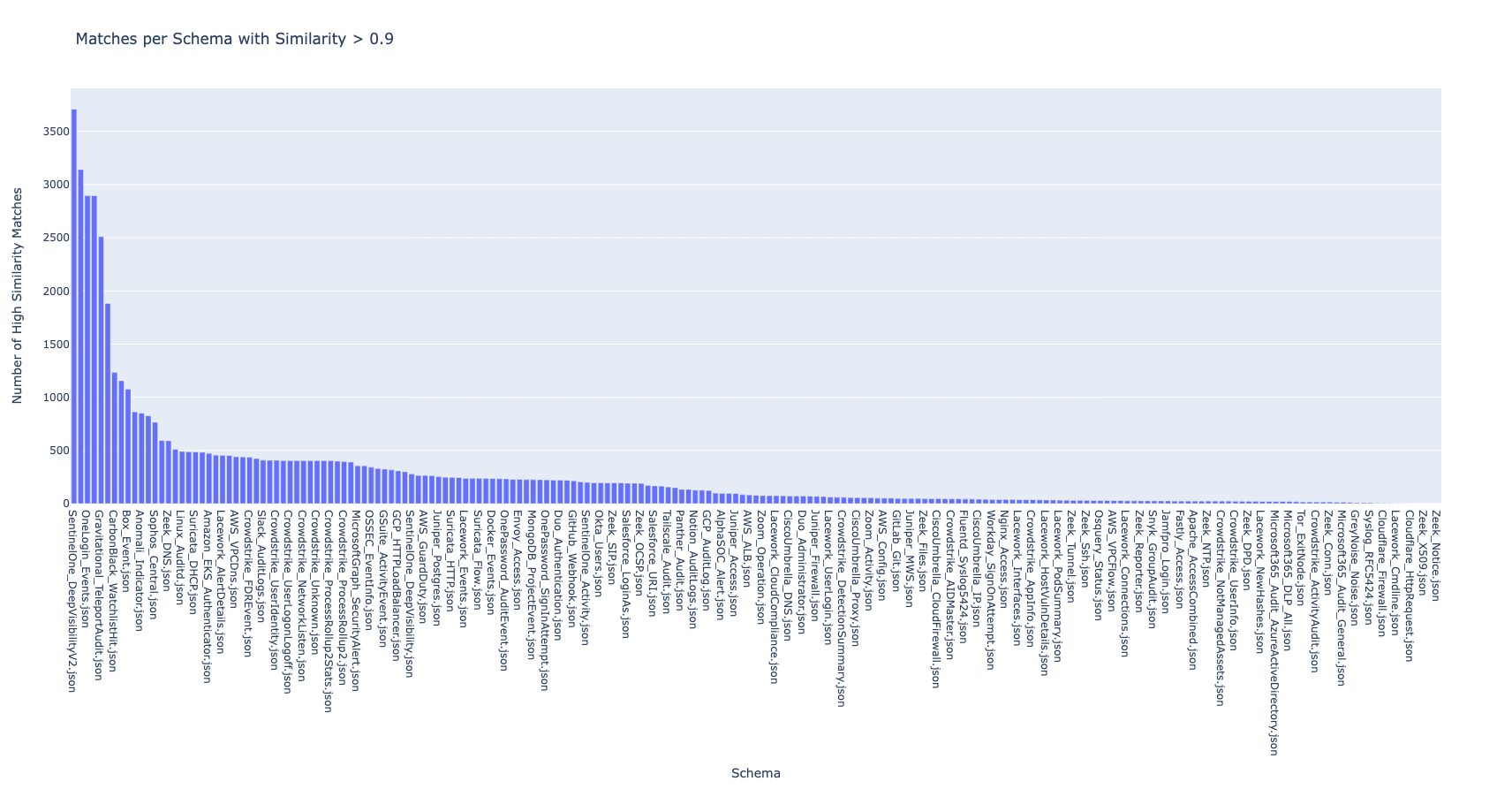
I analyzed 207 schemas and measured duplication rates by identifying fields that were at least 90% similar to others. Here’s what we found:
Zendesk_Audit: 81.06% duplication rate, meaning most of its fields overlap with others.
SentinelOne_DeepVisibilityV2: 33.42% duplication rate, representing 2,960 duplicate fields.
Zeek_OCSP: 7.62% duplication rate.
AWS_CloudWatchEvents: 0.97% duplication rate, showing minimal redundancy.
This chart visualizes the percentage of duplicate fields per log source, highlighting the sources with the most redundancy.
Impact on Log Volume
Duplication rates have a direct impact on the overall volume of log data:
Example: SentinelOne_DeepVisibilityV2, with a 33.42% duplication rate, suggests that over a third of its log data is redundant. Reducing this duplication could cut storage costs significantly and improve analysis speed.
Severe Cases: For Zendesk_Audit, over 80% of the data is duplicated, indicating an urgent need for schema optimization.
Why Duplication Matters
Storage Costs: Duplicate data inflates log volumes, increasing costs for storage and retention.
Processing Delays: Redundant fields add to the computational workload, slowing down analysis pipelines.
Analytical Noise: Duplication complicates threat detection by creating overlapping alerts and redundant data points.
Impact of Duplication on Costs
Managing large-scale log data can be a costly endeavor, especially when duplication is factored in. Using the example of 1 Petabyte (PB) of log data, let’s explore several scenarios that highlight the potential savings and operational efficiency gained from deduplication. These scenarios assume the AWS S3 Standard Storage pricing of $0.023 per GB and a duplication rate of 40.5% based on prior analysis.
Scenario:
Note: This assumes all 207 schemas are being used across the organization.
Log Data Before Deduplication: 1 PB (1,024 TB)
Duplicate Data: 40.5%, or 414.72 TB
Effective Data After Deduplication: 609.28 TB
Costs:
Without Deduplication: Storing 1,024 TB of data costs $24,116.25 per month.
After Deduplication: Storing 609.28 TB of data costs $14,349.76 per month.
Monthly Savings: $9,766.49.
Annual Savings: $117,197.88.
Why It Matters
For organizations managing petabytes of log data, reducing duplication can lead to significant financial savings, while also improving efficiency and streamlining log management processes. This highlights the critical importance of schema optimization in large-scale data storage and analysis.
Addressing Duplication
Streamline Log Management
Organizations should normalize log schemas, consolidating duplicate fields into standardized formats to reduce noise and redundancy.
Leverage Advanced Tools
Using NLP techniques, such as those demonstrated with SpaCy, can help identify and address duplication across log sources.
Implement Smarter Data Management
By filtering and deduplicating logs before storage or analysis, organizations can reduce resource strain and enhance detection workflows.
Conclusion
Our research highlights the significant impact of schema duplication on log volume and processing efficiency. Addressing this issue can result in immediate benefits, from lower storage costs to faster threat detection. The findings underline the value of combining NLP with log analysis for cybersecurity, paving the way for more efficient and streamlined data management practices.
For a detailed breakdown of duplication statistics and results:
Schema Statistics: High-level statistics on total fields, duplicate counts, and percentages per schema.
Duplicate Field Results: Detailed information on field similarities across schemas.
©2025 Asante Babers